Contribute an ELG compatible service¶
This page describes how to contribute a language technology service to run on the cloud platform of the European Language Grid.
Currently, ELG supports the integration of tools/services that fall into one of the following broad categories:
Information Extraction (IE): Services that take text and annotate it with metadata on specific segments, e.g. Named Entity Recognition (NER), the task of extracting persons, locations, and organizations from a given text.
Text Classification (TC): Services that take text and return a classification for the given text from a finite set of classes, e.g. Text Categorization which is the task of categorizing text into (usually labelled) organized categories.
Dependency parsing: Services that perform parsing of sentences to produce trees of syntactic dependencies among their words.
Machine Translation (MT): Services that take text in one language and translate it into text in another language, possibly with additional metadata associated with each segment (sentence, phrase, etc.).
This category can also cover services such as summarization, where the output text is a shorter version of the input but in the same language.
Automatic Speech Recognition (ASR): Services that take audio as input and produce text (e.g., a transcription) as output, possibly with metadata associated with each segment.
Audio Annotation : Services that take audio as input and produce annotations giving metadata about specific time span segments, e.g. speaker diarisation
Text-to-Speech Generation (TTS): Services that take text as input and produce audio as output.
Image Analysis : Services that extract linguistic information from images, e.g., Optical Character Recognition.
Overview: How an LT Service is integrated to ELG¶
An overview of the ELG platform is depicted below.
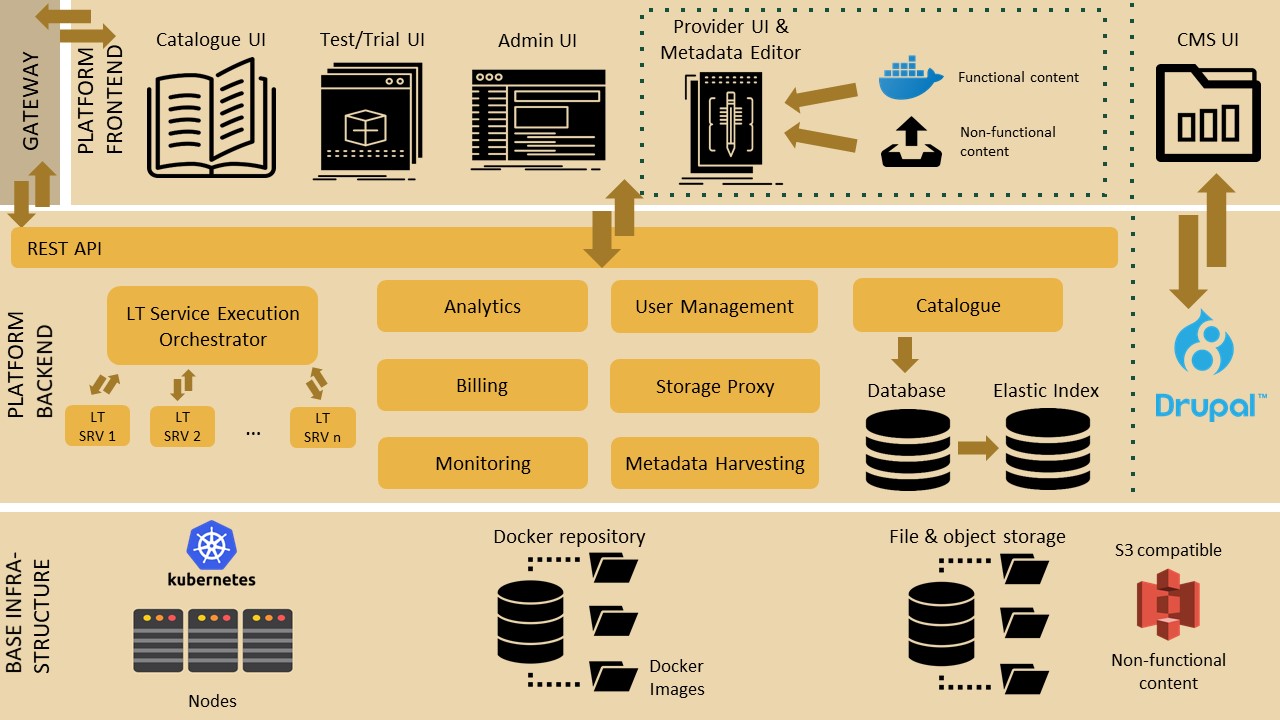
The following bullets summarize how LT services are deployed and invoked in ELG.
All LT Services (as well as all the other ELG components) are deployed (run as containers) on a Kubernetes (k8s) cluster; k8s is a system for automating deployment, scaling, and management of containerised applications.
All LT Services are integrated into ELG via the LT Service Execution Orchestrator/Server. This server exposes a common public REST API (Representational state transfer) used for invoking any of the deployed backend LT Services. The public API is used from ELG’s Trial UIs that are embedded in the ELG Catalogue; it can also be invoked from the command line or any programming language (for more information, see Use an LT service). All ELG-compatible services are offered at a standard endpoint URL of
https://{domain}/execution/process/{ltServiceID}, the service type determines whichContent-Typeor types of data will be accepted -text/plainfor text processing services,audio/mpegoraudio/wavfor audio processing services, or variousimage/*types for image processing services; for more information see Public LT API specification.
{domain}is ‘live.european-language-grid.eu’ and{ltServiceID}is the ID of the backend LT service. This ID is assigned/configured during registration; see section 3. Manage and submit the service for publication - ‘LT Service is deployed to ELG and configured’ step.Note
The REST API that is exposed from an LT Service X (see above) is for the communication between the LT Service Execution Orchestrator Server and X (ELG internal API - see Internal LT Service API specification).
When the LT Service Execution Orchestrator receives a processing request for service X, it retrieves from the database X’s internal REST API endpoint and sends a request to it. This endpoint is configured/specified during the registration process; see section 3. Manage and submit the service for publication - ‘LT Service is deployed to ELG and configured’ step. When the Orchestrator gets the response from the LT Service, it returns it to the application/client that sent the initial call.
0. Before you start¶
Please make sure that the service you want to contribute complies with our terms of use.
Please make sure you have registered and been assigned the provider role.
Please make sure that your service meets the technical requirements below, and choose one of the three integration options.
Technical requirements and integration options¶
The requirements for integrating an LT tool/service to ELG are the following:
Expose an ELG compatible endpoint: You MUST create an application that exposes an HTTP endpoint for the provided LT tool(s). The application MUST consume (via the aforementioned HTTP endpoint) requests that follow the ELG JSON format, call the underlying LT tool and produce responses again in the ELG JSON format. The Internal LT API specification chapter gives a detailed specification of the JSON-based HTTP protocol that you must implement, along with various “best practice” recommendations to help make your service more compatible with other existing services of a similar type.
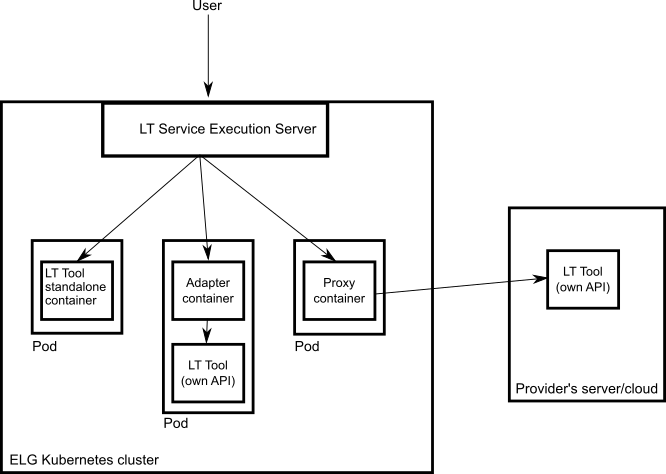
Dockerisation: You MUST dockerise the application and upload the respective image(s) in a Docker Registry, such as GitLab, DockerHub, Azure Container Registry etc. You MAY select out of the three following options, the one that best fits your needs:
LT tools packaged in one standalone image: One docker image is created that contains the application that exposes the ELG-compatible endpoint and the actual LT tool.
LT tools running remotely outside the ELG infrastructure 1 : For these tools, one proxy image is created that exposes one (or more) ELG-compatible endpoints; the proxy container communicates with the actual LT service that runs outside the ELG infrastructure.
LT tools requiring an adapter: For tools that already offer an image that exposes a non-ELG compatible endpoint (HTTP-based or other), a second adapter image SHOULD be created that exposes an ELG-compatible endpoint and acts as proxy to the container that hosts the actual LT tool.
In the following diagram the three different options for integrating a LT tool are shown:
1. Dockerize your service¶
Build/Store Docker images¶
Ideally, the source code of your LT tool/service already resides on GitLab where a built-in Continuous Integration (CI) Runner can take care of building the image. GitLab also offers a container registry that can be used for storing the built image. For this, you need to add at the root level of your GitLab repository a .gitlab-ci.yml file as well as a Dockerfile, i.e, the recipe for building the image. Here you can find an example. After each new commit, the CI Runner is automatically triggered and runs the CI pipeline that is defined in .gitlab-ci.yml.
You can see the progress of the pipeline on the respective page in GitLab UI (“CI / CD -> Jobs”); when it completes successfully, you can also find the image at “Packages -> Container Registry”.
Your image can also be built and tagged in your machine by running the docker build command. Then it can be uploaded (with docker push) to the GitLab registry,
DockerHub (which is a public Docker registry) or any other Docker registry.
For instance, for this GitLab hosted project, the commands would be:
docker login registry.gitlab.com
for logging in and be allowed to push an image
docker build -t registry.gitlab.com/european-language-grid/dfki/elg-jtok
for building an image (locally) for the project - please note that before running docker build you have to download (clone) a copy of the project and be at the top-level directory (elg-jtok)
docker push registry.gitlab.com/european-language-grid/dfki/elg-jtok
for pushing the image to GitLab.
In the following links you can find some more information on docker commands plus some examples:
Dockerization of a Python-based LT tool¶
The ELG Python SDK provides tools to simplify the implementation and packaging of ELG LT services in Python. A tutorial example can be found in the Python SDK chapter, and a complete example of a tokeniser service is available on the ELG GitLab.
Dockerization of a Java-based tool¶
A helper library is available to make it as easy as possible to create ELG-compliant tools in Java using the Micronaut framework. An example of a tokeniser service is available on the ELG GitLab.
Docker image best practices¶
Keep your image small - larger images require more storage space and take longer to start up when a service must scale in response to demand. There are a number of techniques to keep your images as small as possible, including:
use the smallest available base image, for example with Python-based services prefer the
python:3.x-slimbase image over the fullpython:3.xif you need to install additional tools or libraries be sure they are actually required for your particular use case - do not blindly include all the “recommended” or “suggested” dependencies of a package by default, only install the ones you really need
be careful with
RUNcommands in your Dockerfile, remember that eachRUNcreates a new layer so if you create some files in oneRUNand then delete them in a laterRUN, the files will still take up space in the final image (albeit hidden in a lower layer). In particular when installing packages withapt-get, combine the update, install and cleanup into one RUN command rather than running them separately
Use the least privilege necessary - many Docker images will run as the
rootuser by default, but this is rarely necessary in practice. Create an unprivileged user with a fixed (non zero) user and group ID such as 1001, and include aUSER 1001:1001instruction in your Dockerfile to make the image run as the unprivileged user 2certain things such as binding to port numbers less than 1024 can only be done by the
rootuser, so you may need to re-configure your software if it is based on a web server such as Apache HTTPD or nginx that normally expects to use port 80. The ELG platform can work with endpoints exposed on any port, port numbers 8000 or 8080 are common choices for a non-root web server
Be self-contained - try to include within the image all data that your service requires in order to operate. The image should not need to download additional data from the internet while it is running, unless it is a proxy to a remote service running elsewhere
for example, Python libraries such as HuggingFace Transformers will by default download their model files from the internet the first time a particular model is requested, and cache it locally for future use. However, when running in a Docker image every time is the “first time”, and the container will have to download the model every time it starts up. To avoid this, add a
RUNstep to your Dockerfile to load the model once during the build and cache it within the image, meaning the container does not need to download it again at startup.
Be defensive - where possible, try to detect situations such as your code approaching its memory limit, pathological inputs that take longer than usual to process, etc. and return sensible error messages. But conversely, if your software does reach an unrecoverable state (or a state from which it would take significant time to recover) then the best course of action is generally to exit the whole process, and let the platform restart the container in a clean state.
2. Describe and register the service at ELG¶
You can describe and register the service
using the ELG interactive editor (see Use the interactive editor), or
by uploading a metadata file that conforms to the ELG schema in XML format (see Create and upload metadata files).
In both modes, you MUST indicate that it is an ELG compatible service. More specifically, if you use the interactive editor, select the Service or Tool form and, when prompted, select Yes.

If you decide to upload a metadata file, you MUST check the box next to ELG-compatible service at the upload page.
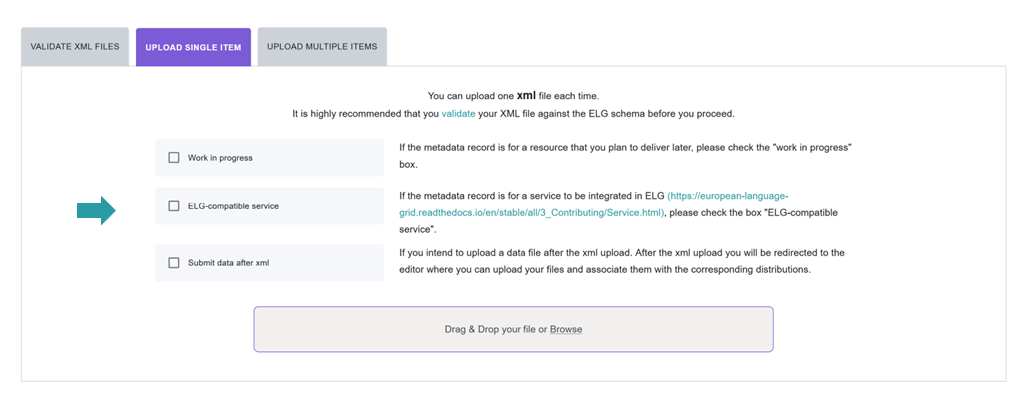
Depending on your answer, the respective box will/will not be checked in the editor. You can change your decision anytime through the editor form.
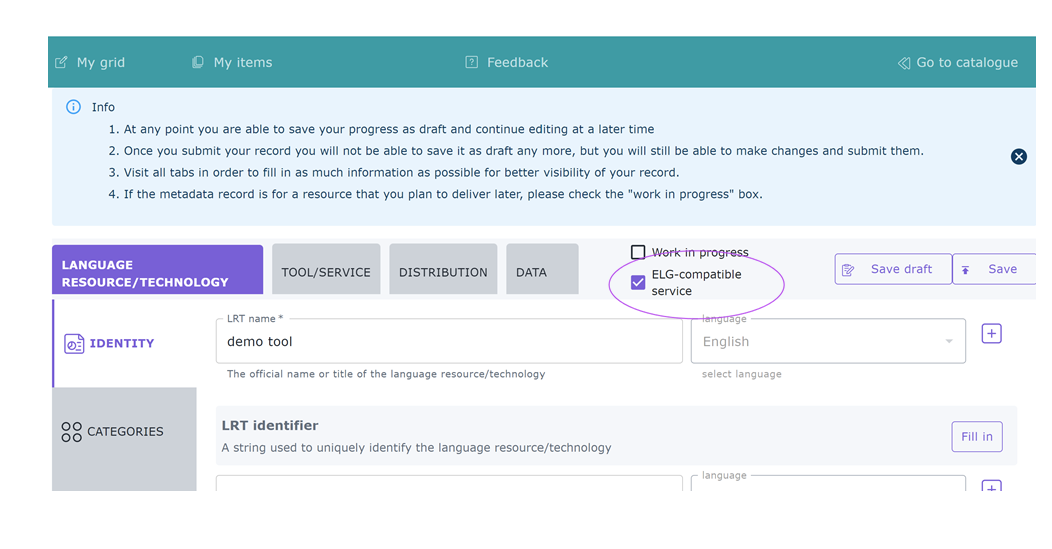
The service MUST be described according to the ELG schema and include at least the mandatory metadata elements.
The following figure gives an overview of the metadata elements you must provide 3 for an ELG-compatible service, replicating the editor (with sections horizontally and tabs vertically) so that you can easily track each element. In the editor, all elements, mandatory or not, are explained by definitions and examples.
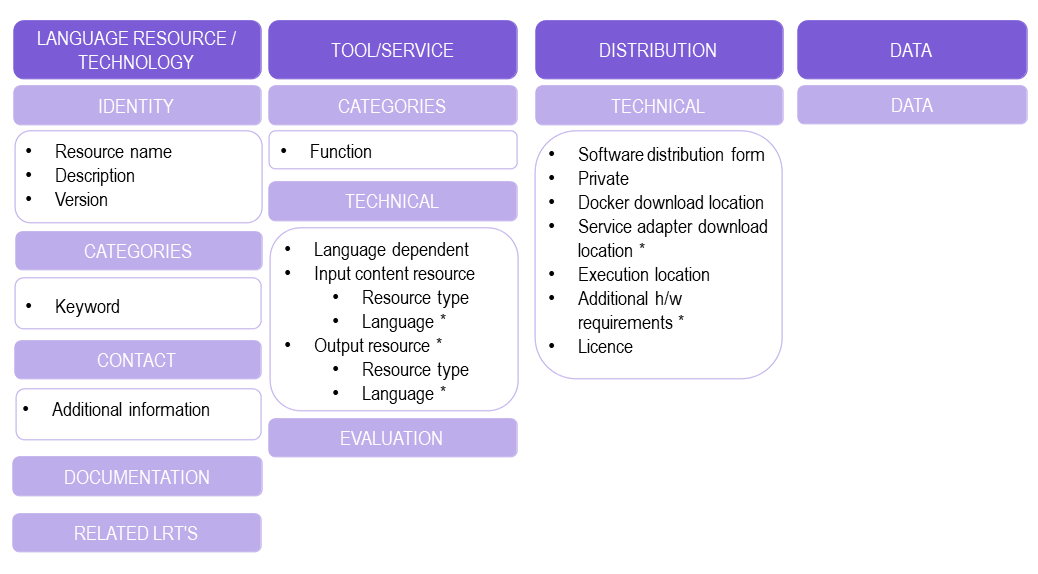
To describe any resource efficiently you need to name it, provide a description with a few words about it and indicate its version 4. Then, one or more keywords are asked for the resource and an email or a landing page for anyone who wishes to have additional information about it.
For services, you must also specify the function (i.e., the task it performs, e.g. Named Entity Recognition, Machine Translation, Speech Recognition, etc.), details of any parameters that the service accepts, and the technical specifications of its input, at least the resource type it processes (e.g. corpus, lexical/conceptual resource etc.). It is highly recommended to provide at least one sample of input that will produce meaningful results from your service; the samples you provide will be listed on the “try out” tab offering users a quick way to see your service in action. The samples should be plain text, audio, or an image, as appropriate for your service; if your service takes parameters then you can instead specify the sample as JSON following the LT Service Internal API format 5 to associate specific parameter values with each sample. You must also select whether it is language independent and, if not, specify the input language(s). For Machine Translation services you should specify the translation target language(s) on the service output resource; for other service types you should list the same languages for the output as you selected for the input.
You also have to describe independently each distributable form of the service (i.e. all the ways the user can obtain it, e.g., in a downloadable form, as a file with the source code or a docker image). For each distribution, you must always specify the licence under which it is made available. In the case of ELG compatible services, one Software Distribution with the following elements MUST be included in the metadata record. The editor will guide you through the process of filling them in.
Software distribution form (
SoftwareDistributionForm): For ELG compatible services, use the value docker image (http://w3id.org/meta-share/meta-share/dockerImage).Docker download location (
dockerDownloadLocation): Add the image reference in the usual form you would pass todocker pullin order to download the image. For images hosted on Docker Hub this can be<username>/<image>:<tag>, for images hosted elsewhere include the registry name in the normal way, e.g.registry.gitlab.com/european-language-grid/example:1.0.Note that ELG requires that docker images be properly tagged with a named tag such as
:1.0.0or:v2-elgetc. In particular your submission will be rejected if you use the:latesttag, which typically changes over time to point to different versions.
Service adapter download location (
serviceAdapterDownloadLocation): If your service is implemented using an adapter (see technical requirements above) then you must provide the image reference for the adapter image in the same way. If your service does not use an adapter, leave this blank.Execution location (
executionLocation): Add here the REST endpoint at which the LT tool is exposed within the Docker image. This should be a URLhttp://localhost:<port>/<path>including the port number on which your service listens for connections (if not the default HTTP port 80) and the URL path at which the endpoint can be found.Private (
privateResource): Specifies whether the resource is private so that its access/download location remains hidden when the item is published in the ELG catalogue.Additional h/w requirements (
additionalHwRequirements): A short text where you specify additional requirements for running the service, e.g. memory requirements, etc. The recommended format for this is: ‘limits_memory: X limits_cpu: Y’.
3. Manage and submit the service for publication¶
Through the My items page you can access your metadata record (see Manage your items) and edit it until you are satisfied. You can then submit it for publication, in line with the publication lifecycle defined for ELG metadata records.
At this stage, the metadata record can no longer be edited and is only visible to you and to us, the ELG platform administrators.
Before it is published, the service undergoes a validation process, which is described in detail at CHAPTER 4: VALIDATING ITEMS.
During this process, the service is deployed to ELG, configured and tested to ensure it conforms to the ELG technical specifications. We describe here the main steps in this process:
LT Service is deployed to ELG and configured: The LT service is deployed (by the validator) to the k8s cluster by creating the appropriate configuration YAML file and uploading to the respective GitLab repository. The CI/CD pipeline that is responsible for deployments will automatically install the new service at the k8s cluster. If you request it, a separate dedicated k8s namespace can be created for the LT service before creating the YAML file. The validator of the service assigns to it:
the k8s REST endpoint that will be used for invoking it, according to the following template:
http://{k8s-name}.{k8s-namespace}.svc.cluster.local{path}.{k8s-name}is the k8s service name for the registered LT tool,{k8s-namespace}is k8s namespace for the registered LT tool,{path}is the path where the REST service is running at. The{path}part can be found in theexecutionLocationfield in the metadata.An ID that will be used to call it.
Which “try out” UI will be used for testing it and visualizing the returned results.
LT Service is tested: On the LT landing page, there is a Try out tab and a Code samples tab, which can both be used to test the service with some input; see Use an LT service section. The validator can help you identify integration issues and resolve them. This process is continued until the LT service is correctly integrated to the platform. The procedure may require access to the k8s cluster for the validator (e.g., to check containers start-up/failures, logs, etc.).
LT Service is published: When the LT service works as expected, the validator will approve it; the metadata record is then published and visible to all ELG users through the catalogue.
Frequently asked questions¶
executionLocation? For example, an IE tool has to expose a specific path or use a specific port?``http://{k8s-name}.{k8s-namespace}.svc.cluster.local{path}``, which assumes that the service is exposed to port 80.dockerDownloadLocation) and each of them has to listen in a different HTTP endpoint (executionLocation) but on the same port. E.g, http://localhost:8080/NamedEntityRecognitionEN, http://localhost:8080/NamedEntityRecognitionDE.:latest or a similar tag that is likely to be mutable. The best type of tag to choose is one that matches your metadata version number, e.g. :1.0.2, or something obviously ELG-specific e.g. :v1.0-elg.additionalHWRequirements metadata element (see the MT example above) or by communicating with the ELG administrators.- 1
Services running remotely outside the ELG infrastructure are marked as such with a tag on their view page.
- 2
Always use the numeric form
USER 1001:1001rather than the symbolic formUSER ltuser:ltgroup, as the numeric form means that the image can be verified to run as non-root simply by looking at the metadata.USERdeclarations that use symbolic names can only be verified as “not UID 0” once the container is actually running.- 3
You must fill in at least the mandatory elements for the metadata record to be saved. In addition, you may be required to fill in specific mandatory if applicable elements (indicated in the figure with an asterisk), depending on the values you provide for other elements.
- 4
If no version number is provided, the system will automatically number it as “1.0.0” with an indication that it has been automatically assigned. The version number can appear in the public API endpoint URL however, so we strongly recommend you do specify a particular version number, ideally using the Semantic Versioning (https://semver.org/) scheme.
- 5
For services that process text, specify the “sample text” as
{"type":"text", "content":"The actual text", "params":{...}}. For services that process images or audio, specify{"type":"audio|image", "params":{...}}in the “sample text” box and upload the actual audio or image using the browse button.