Validate an ELG compatible LT service (at technical/metadata level)¶
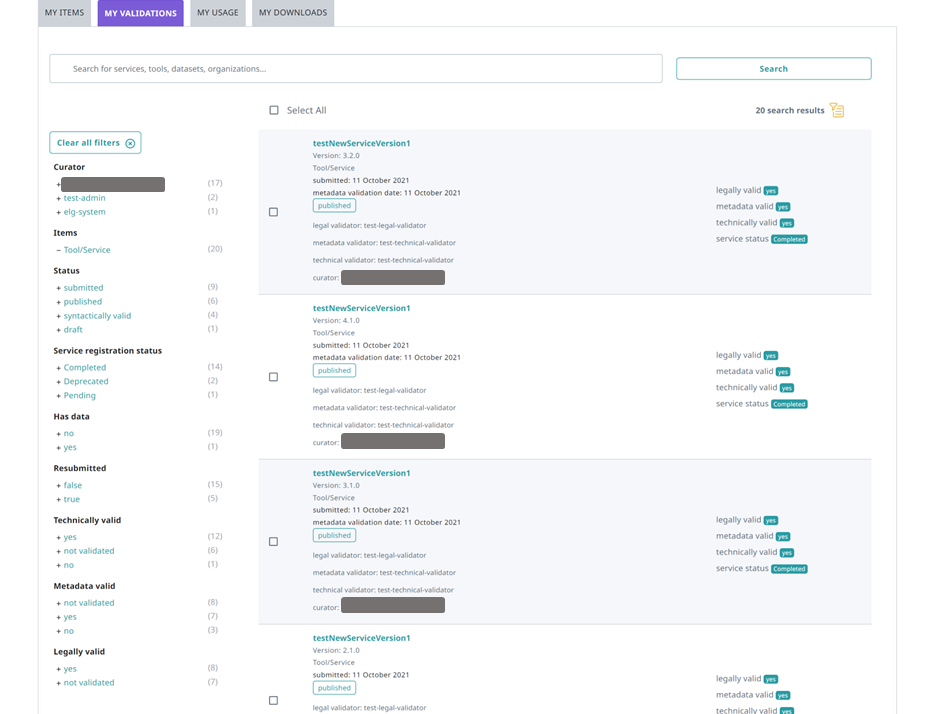
See here how to access the My validations, which is the list of items assigned to you for validation. You can, then, apply the filters on the left to help you reduce the number of items presented or search for a specific item using the search box.
Deployment of the service at ELG and service registration¶
Before you perform the technical/metadata validation, you must first deploy the service at ELG and register it at the ELG catalogue. First you should verify that the metadata record follows the standard ELG conventions, in particular:
the docker download location (and service adapter download location if relevant) must be an image reference suitable for use with
docker pull, not a link to a Docker Hub or GitLab container registry web page, and the image tag must be an immutable tag (such as a version number) and not a “rolling” tag such as “latest” or “master”. Ideally the tag should match the metadata record version number.the execution location must be of the form
http://localhost:<port>/<path>for non-public services, you will need to ensure that you have created a suitable namespace (if one does not already exist for this provider) and any necessary secrets for the image pull credentials. You may need to contact the curator directly to obtain this information.
If this is not the case, reject the record and ask the provider to correct these items.
You can now deploy the LT service into the ELG kubernetes cluster: For this you have to create the required yaml file, as in the example below, in the respective GitLab repository and branch.
image : "registry.gitlab.com/qurator-platform/dfki/srv-ler:1.0.569798760"
limits_memory: 2048Mi
scalability: "dynamic"
minScale: "1"
To create the yaml file, you will need the docker_download_location, service_adapter_download_location, execution_location metadata element values, that you will find on the service registration form, and any additional_hw_requirements from the “download/run” tab. By selecting one of the metadata records on the My validations tab, you will be directed to its view page; click on Actions and select Perform service registration.
When the yaml file is commited/pushed, the automatic CI/CD deployment pipeline of ELG will be notified and install the LT service to the respective kubernetes cluster; for instance, the master branch is used for the production ELG cluster, while the develop branch is used for the development cluster. You will also need access to the cluster so that you can check which containers/pods are running, inpect the logs and statuses of the containers, etc.; for this, you will receive the required information and credentials from the ELG technical team.
On the service registration form, you must also provide the following necessary information
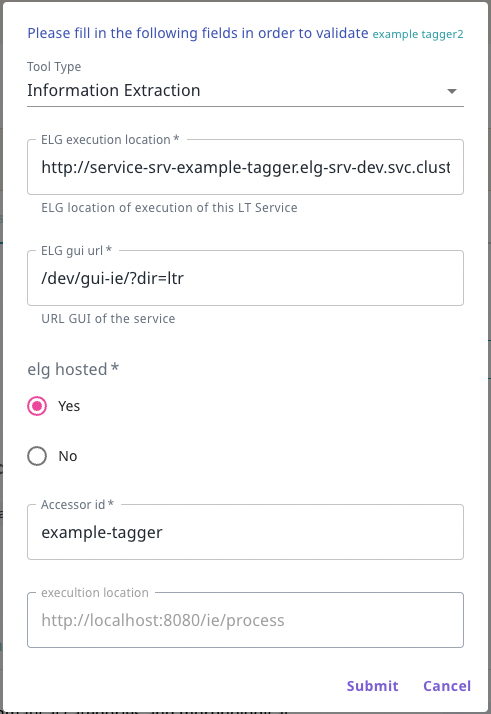
select the
Tool typevalue (IE, MT, ASR, etc.), depending on the type of service you validate. The metadata of the service will help you decide which is the appropriate value;fill in the
ELG execution location; the value of this field depends on how the LT service is deployed into the cluster, which namespace was used, etc. As described here, this field follows this template:http://service-{name}.{namespace}.svc.cluster.local{/path}. The{name}and{namespace}are the identifier under which the service is deployed (typically the name of the defining YAML file) and the Kubernetes namespace used. The{/path}part is the path to the endpoint within the running container and can be derived from theexecutionLocationelement value of the metadata record. For this reason, theELG execution locationfield is pre-filled with theexecutionLocationvalue, so that you can change only the part that is required. 1set the
Elg gui url; the standard set of GUIs available in the ELG platform by default are as follows, and thegui-ieones can take additional parameters that are described below./dev/gui-ie/for IE tools that take text as input and return a response that is eitherannotations(relative to the original text), ortextsthat should be shown instead of the original input text,/dev/gui-ie/index-mt.htmlfor MT and similar services that take text as input and return a response of typetextsthat should be shown along with the original input text,/dev/gui-ie/index-asr.htmlfor ASR services that take audio as input and returntexts,/dev/gui-ie/index-audio-annotation.htmlfor “audio annotation” services that take audio as input and return anannotationsresponse where the start/end of each annotation is a possibly-fractional number of seconds from the start of the audio stream,/dev/gui-ie/index-text-classification.htmlfor Text Classification services that take text input and return aclassificationresponse,/dev/gui-ie/index-image.htmlfor services such as OCR that take images as input and returntextsas output,/dev/gui-ie/index-dependency.htmlfor dependency parsers, or/dev/gui-tts/for TTS services.
Depending on the value that you have set, the appropriate try out UI will be displayed in the respective tab of the landing page of the LT service.
Note
If there is no available/appropriate try out UI for the specific service or for any other reason, you can disable/hide the try out UI tab by setting none to the Elg gui url field.
select the appropriate value for the
elg hostedelement - a service is considered “ELG hosted” if the processing logic runs entirely within the ELG cluster and does not involve making network connections to non-cluster addresses. Services that are proxies to a remotely-hosted endpoint are labelled as such since the ELG cannot offer the same availability guarantees as for ELG-hosted services;set the
Accessor idof the service. This is the final segment of the ELG public API endpoint at which the service can be called (/execution/process/{accessor-id}), so must be a valid URL path segment - the recommended form is “kebab case”, i.e.lower-case-with-hyphens. If the service you are validating is a new version of an existing published service then it will share the same accessor ID, but other than this the IDs for distinct services must be unique. For a brief overview of the LT REST API, see this section.the
execution locationshows the respective metadata value, it is read-only for reference when setting the “ELG execution location” above;the
docker download locationis pre-filled with the respective metadata value;the
private resourceelement has a pre-selected value with the provider’s choice, indicating whether or not they want ELG users to be able to download the Docker image to run it on their own hardware;set the value of
statustocompletedand click on Submit in order to activate the service.
Configuration parameters for gui-ie
The gui-ie trial GUIs support a number of additional URL parameters to fine-tune their behaviour, which can be appended as a query string to the URL in the normal way (?param1=value1¶m2=value2&...):
Text direction (left-to-right or right-to-left). Note that it is worth specifying
ltrexplicitly for left to right languages, so it shows correctly even for users whose browser defaults to RTL (e.g. Arabic speakers)for ASR services use
/dev/gui-ie/index-asr.html?dir=ltror/dev/gui-ie/index-asr.html?dir=rtlfor left-to-right and right-to-left directions for the output transcript, respectively.Similarly, for IE services
/dev/gui-ie/?dir=ltror/dev/gui-ie/?dir=rtlcontrols the direction of the input text field and the resulting annotated text.For MT services use
srcdirandtargetdirparameters (e.g.index-mt.html?srcdir=ltr&targetdir=rtl) to specify the text direction of the input and output text separately.
Default text roles - If a service returns a “texts” response which does not include explicit “role” values on each element then the various
gui-ieUIs assume a role of “alternative” by default (treating multiple text elements as alternative translations/transcriptions of the input with only one displayed at a time).If this is not correct you can override the default role or roles with a
?roles=...parameter. This is a list of one or more role names separated by hyphens, representing the default role for elements at each level of the texts tree (note that if an element specifies its own “role” this will always take precedence over the default).For example
?roles=segment-alternativewould mean a list of segments (displayed one after the other), where each segment is a list of alternatives with buttons to move between them.If there are more levels of texts in a given response than role names in the
rolesparameter then the last name in therolesparameter is used as the default for subsequent levels. For example?roles=segmentwould work for a response of segments that can contain sub-segments nested to any level,?roles=alternative-segmentwould support arbitrarily nested segments within the top level list of alternatives. 2This parameter is particularly useful for services that return output as a list of tokens rather than as flat text with standoff annotations -
?role=sentence-tokenwould mean a list of sentences where each sentence is a list of tokens,?roles=tokenwould be a flat list of tokens. The role “token” (or “word”) is special, a list of tokens will be displayed as a single string with the tokens separated by spaces and with a “token” standoff annotation over each one. Any “features” of the token will be treated as features of the synthesized annotation instead, and any annotations at the parent level (with their offsets in terms of numbers of tokens) will be rendered as spanning over the synthetic tokens.
Hiding some annotations - by default all annotations returned by the service are selected to be shown as colour highlights, as well as “token” annotations synthesized by
?roles=token. This is not always desirable, for example in a service that returns standoff annotations over a list-of-tokens “texts” response, you may prefer to hide the token annotations by default so that the spanning annotations are more easily visible. Two parameters control this:?show=type1&show=type2&...causes only the specified types to be shown by default, and all other types to be hidden?hide=type3&hide=type4&...causes the specified types to be hidden by default, e.g.?roles=sentence-token&hide=tokenhides the synthetic token annotations in a list-of-tokens responseIf there are no
showoptions then every type is shown unless explicitly hidden by ahideNote that all annotation types remain available to be shown if the user requests them, these parameters only control which boxes are ticked by default
Audio format and sample rate - By default the live recording option in audio input GUIs
index-asr.htmlandindex-audio-annotation.htmlwill encode the audio as 2 channel (stereo) MP3 at the default sample rate of the audio input device.If the service requires WAV instead of MP3 specify
?audioFormat=wavTo specify mono instead of stereo:
?audioChannels=1To specify a specific sample rate:
?audioRate=16000E.g. ASR for German (a left-to-right language) that requires 16kHz mono WAV would be
/dev/gui-ie/index-asr.html?dir=ltr&audioFormat=wav&audioChannels=1&audioRate=16000
For dependency parser services in particular (/dev/gui-ie/index-dependency.html) there are many different ways in which a dependency tree can be represented in an “annotations” or “texts” response, and thus a relatively large number of configuration options available. The most up-to-date documentation on these options can be found in the gui-ie documentation at GitLab.
Technical/Metadata validation¶
Now that the service is deployed and registered you may proceed to the technical & metadata validation step.
For technical validation you should verify that the service meets the ELG API specification (in both the success and failure cases) and that its functionality matches its metadata description. Test the service using the configured try out GUI, and possibly also with other client tools such as curl or the Python SDK as detailed on the “code samples” tab. Pay particular attention to the following:
Sample data: has the provider supplied sample input data for the service? If so, does it produce a valid result for every sample? If not, is it obvious to users what kind of data the service requires? If the service accepts input in multiple languages, is there a good spread of samples across all the languages? We do not necessarily require a sample for every language but samples in at least two or three major languages would be preferred. If the service takes parameters that do not have sensible defaults, then the samples should include appropriate parameter settings. If there are no samples in the metadata and a typical user would not be able to easily tell what kind of data to supply, reject the submission and ask the provider to include at least one sample.
Response formats: is the response format consistent with ELG norms? If the service returns annotations over text data do they appear in the correct places in the try out GUI (this is a quick check that the provider has understood the zero-based-character-offsets model of standoff annotation)? If a texts response includes explicit “role” declarations are they appropriate (e.g. the provider has not declared “segment” when the result is actually “alternative” or vice versa)? Are audio annotations given in terms of fractional seconds (not number of samples or some other measuring scale)?
Error responses: when things go wrong, does the service return well-formed and appropriate errors? If every failure returns just “Internal error during processing: Invalid response” then this may be an indication that the LT service is returning invalid error responses (e.g. a framework-default HTML error page instead of an ELG JSON failure message). If you have access to the logs in the Kubernetes cluster then there may be more information in the
restserverlog data, for particularly complex cases you may need to pull the image to your local Docker and call its internal API endpoint directly to see precisely what response it is returning to the restserver.If a provider has used their own non-standard message codes then these must not start with the
elg.prefix. This prefix is reserved for messages in the standard bundle, if a service uses a non-standard code with anelg.prefix it should be rejected and the provider asked to use their own prefix instead.
Parameters: Are all parameters properly declared in the service metadata, with the correct types, defaults and enumerated values as appropriate? Test the service with as many combinations of parameter values as you reasonably can (e.g. if it has two parameters, both optional, then try it with neither parameter, with one or the other, and with both). If any of the parameters are required but do not have default values, then every sample should provide appropriate parameter values alongside the input (this can be done by providing the sample as JSON rather than plain text/audio) - if the samples do not include suitable parameter settings you may need to reject the record and ask the provider to modify the samples.
Any issues should be raised with the provider, either directly by email or by “rejecting” the submission via the validation form.
Note
You should make it clear to the provider that if they need to modify their code and create a new Docker image then they must push the new image under a different tag, and update the “docker download location” in their metadata to match - the ELG infrastructure caches images at the point of deployment and will not check for subsequent updates to the same image tag.
For the Metadata validation you are asked to check whether the values of the following elements are included in the metadata record and whether their values match the description of the service:
function: important for findability purposes
input & output language(s): for MT services, the output language(s) must be included; for services of other types, the output language is not recommended (redundant information)
input & output data type(s): important for findability and interoperability purposes
output annotation type(s): if the tool is of the IE type, it’s recommended that this element has values for the types of information annotated/extracted
resource creator(s) and publication date: although not mandatory, they are useful for citation purposes;
domain(s): recommended for findability purposes; if possible, recommend the use of an existing value.
documentation: user and installation manuals for services are recommended; publications describing the use of the resource are also welcome
distribution(s): if a resource is available in multiple forms (e.g. as a functional service, but also as source code or downloadable form), it’s recommended to describe them as different distributions. Every functional service must have one distribution that is “docker image”, but may also have a separate distribution, e.g. linking to the source code on GitHub/GitLab.
for the “docker image” distribution as mentioned above, the image tag must not be
:latestor another similar rolling tag - ideally the tag should include an explicit version number that matches the metadata record version.
Also check the “version” field of the metadata record and ensure that it has been changed from the default “1.0.0 (automatically assigned)” value. For functional services the version should be a “semantic version” as described at https://semver.org, without any spaces or other unusual characters, as it will be used as a URL query parameter in the public API endpoint to distinguish between different versions of the same service.
When you have made all the checks you need and have decided whether to approve or reject the submission, go to the item view page and click on actions then “Perform metadata/technical validation” to proceed.
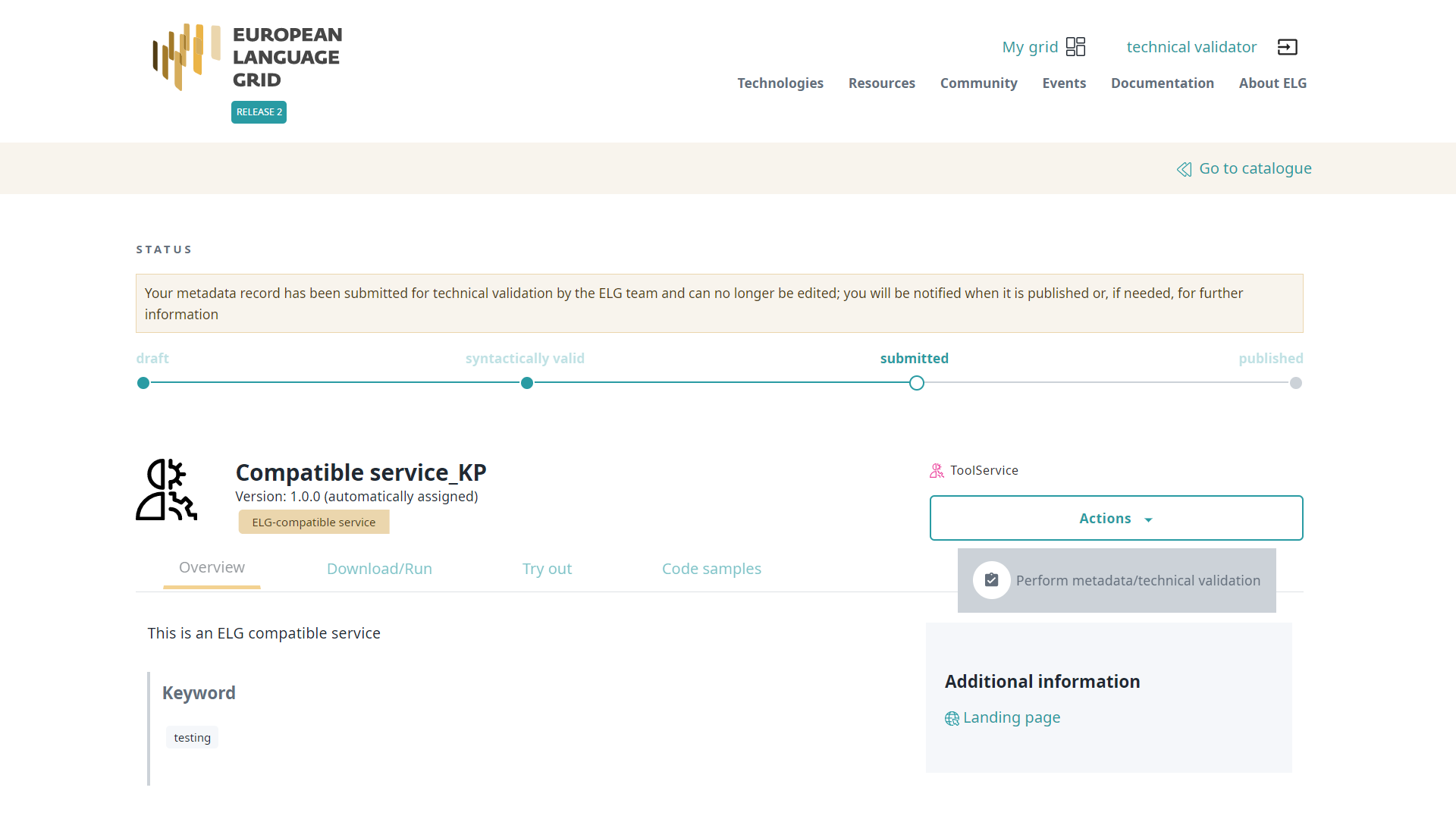
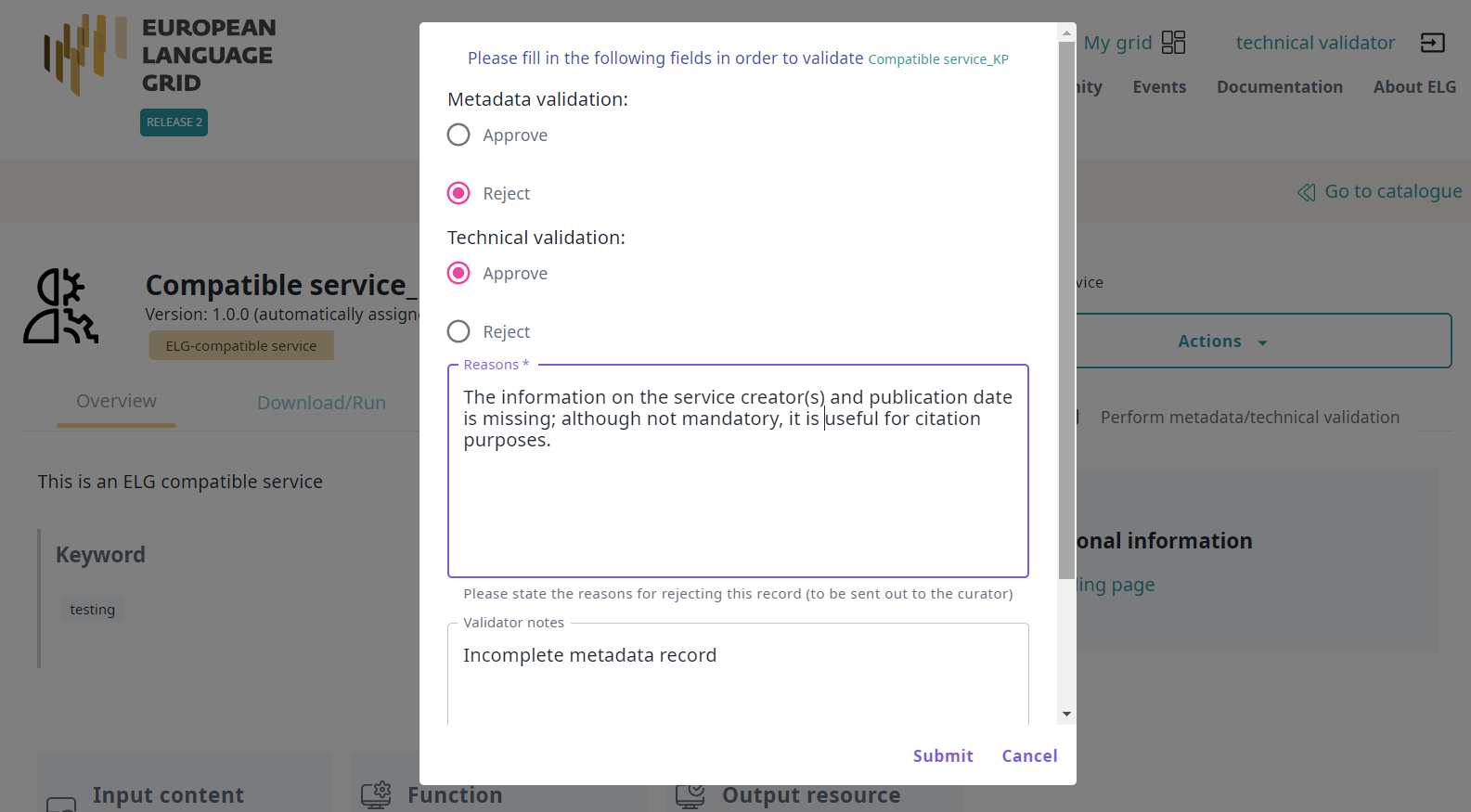
A form will open in which you must say whether you Approve or Reject the item after the technical and metadata validation. You must provide both answers before you submit the form.
If you are satisfied, approve both types of validation and click on Submit.
If not, set the value of the Technical validation and/or the Metadata validation (depending on the source of the issue) to Reject. This will generate a new field where you can write the recommendations you would like to share with the curator. You can also add comments in the Validator notes field which will be visible only to other validators. When you have finished, click on Submit.
The provider will be notified by email (containing the review comments) in order to update the record. Once finished, the provider will re-submit the record for publication and you will be notified to perform the validation.
Note
Please, keep in mind that an item is published only when it has been approved at all validation levels (technical, metadata and legal).
Registering and validating services in bulk¶
If you have many similar services to register at the same time (e.g. a set of translation services for different language pairs), then there is a facility to register them all as a batch by uploading a tab-separated file. To use this, click the Batch service registration button in the right hand column of “my grid”. On this page you can download a TSV file with all your “new” and “pending” service registrations, which you can then edit in any way you see fit (using a spreadsheet, via a programming language like Python, etc.).
The TSV has columns for the required service registration parameters of “tool type”, “ELG execution location”, “GUI URL”, “ELG hosted”, “accessor ID” and the “status” flag (initially NEW, you must set it to COMPLETED), as well as read-only columns with additional information that may be useful when completing the required parameters. Once you have filled in all the required columns you can upload the resulting TSV back to the Batch service registration page in order to complete all the registrations in one operation.
Once all the services are registered you can also perform technical and metadata validation on the records in batches as well as individually - select the checkboxes that appear next to the relevant services in the My validations list and select from the Actions box at the top of the list.
Registering and validating services that were unpublished¶
In rare cases, resources that have been published may be requested to be unpublished. In this case, the metadata record will return to internal status so that the provider can edit the metadata and resubmit for publication. If there are any changes in one of the metadata elements docker download location, service adapter location or execution location, the service registration status changes to “pending”. In this case, you must check the changes, and make sure the service is still working as it should before changing the status to “completed” and perform the validation. If there are no changes, the status remains as “completed”, yet you are advised to still test the operation of the service before performing the validation.
Footnotes
- 1
In almost all cases no port number is required, as knative services are always exposed as port 80. However some legacy “static” services may require a different port number.
- 2
Note there is currently no way to specify a different role for just the leaf nodes of a variable-depth “texts” structure (e.g. a tree of sub-segments terminating in “token” leaf nodes) - role overrides are applied from the top level down. If such a use case arises report an issue on https://gitlab.com/european-language-grid/usfd/gui-ie